Introduction
Nowadays most companies use geographic distributed platforms to better serve their customers. It is quite common to see companies with datacenters in North America, Europe and Asia; each site hosting databases and shared data. In some cases the data is simply spread around for better accessibility; in other cases it is localized and different on each geographic location; in most cases a mix of the two.
Useless to say that most of the solutions were implemented using MySQL, and asynchronous replication. MySQL Asynchronous replication had being the most flexible solution, but at the same time also the most unreliable given the poor performance, lack of certification and possible data drift.
In this scenario the use of alternative solutions, like MySQL Synchronous (galera) replication had being a serious challenge. This because the nodes interactions was so intense and dense, that poor network performance between the locations was preventing the system to work properly; or to put it in another way, it was possible only when exceptional network performances were present.
As such horrible solutions like the following are still implemented.
I assume there is no need to explain how multi-circular solutions are a source of trouble, and how they seems to work, until you realize your data is screw.
So question is, what is the status of MySQL Synchronous replication and there is any possibility to successfully implement it in place of Asynchronous replication?
The honest trustable answer is it depends.
There are few factors that may allow or prevent the usage of MySQL Synchronous replication, but before describe them, let us review what had happened in the development of galera 3.x that had significantly changed the scenario.
The first obvious step is to validate the network link, to do so I suggest to follow the method describe in my previous article (Effective way to check network connection).
Once you had certify that, the next step is to design correctly the cluster, assigning the different geographic areas to the logical grouping with the segment feature Galera provide, to know more about segments (geographic-replication-with-mysql-and-galera)
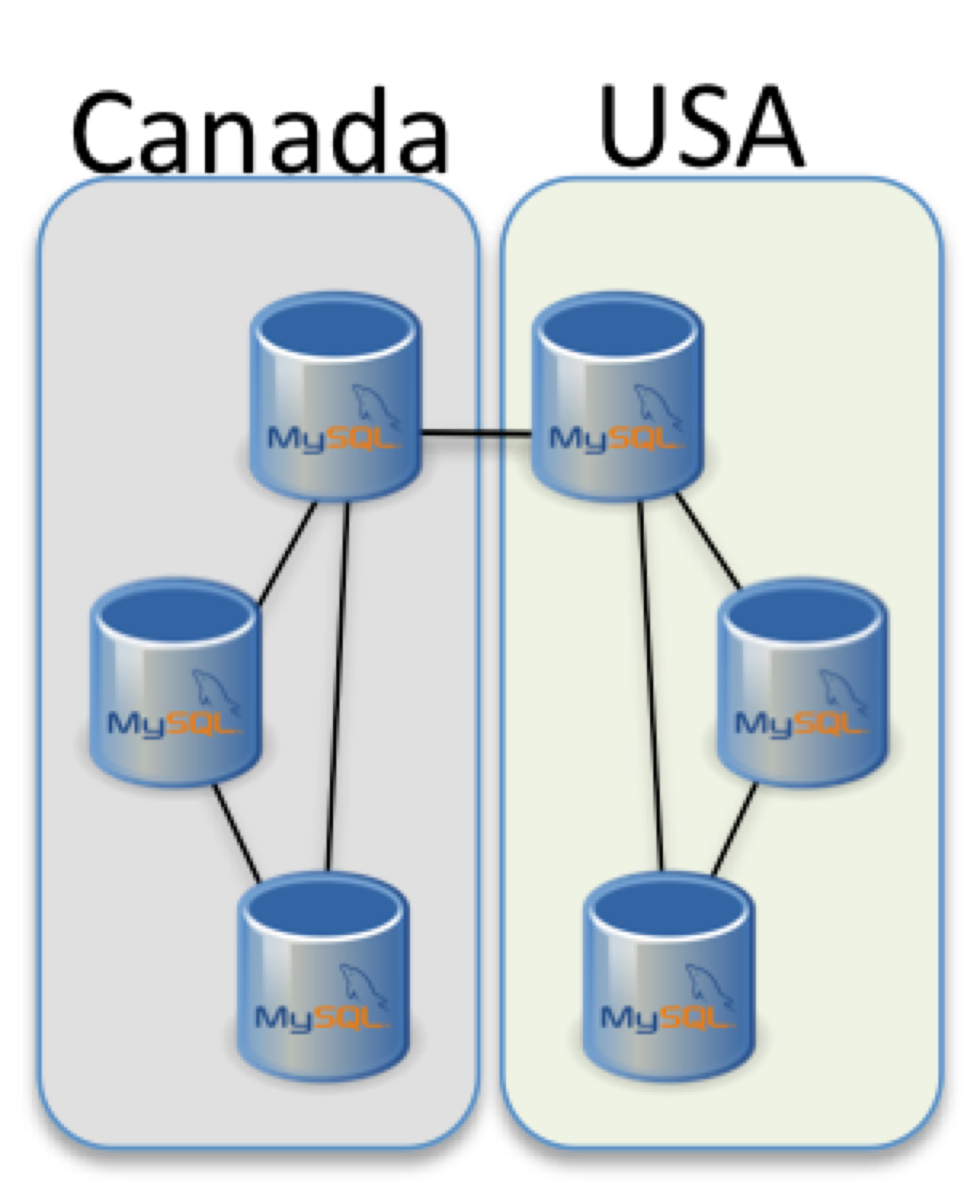
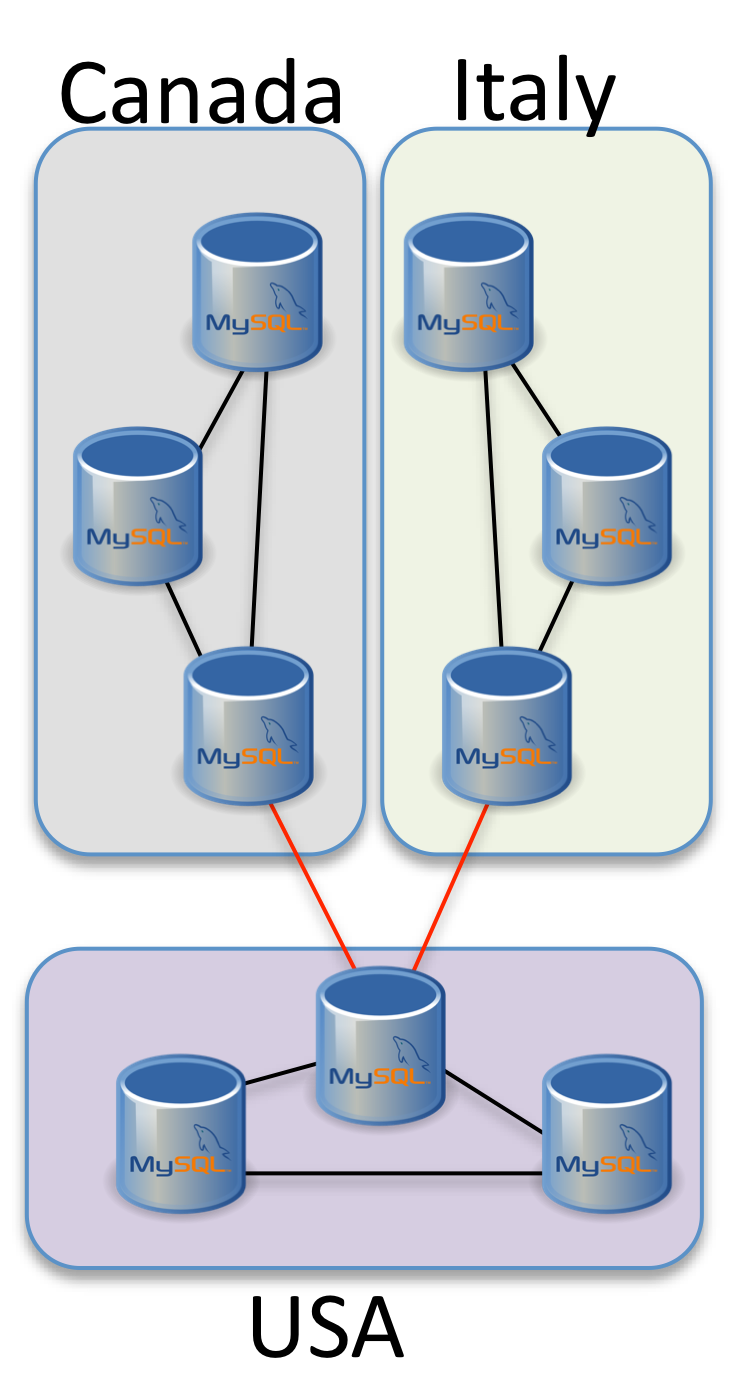
Assuming two scenarios, one is for simple Disaster Recovery, while the second for data distribution.
The first one will be locate on same continent, like Italy and France or Canada and USA. While the second can be distributed like Italy, Canada and USA.
We can come up with a schema for this two solutions that looks like:
 |
OR | 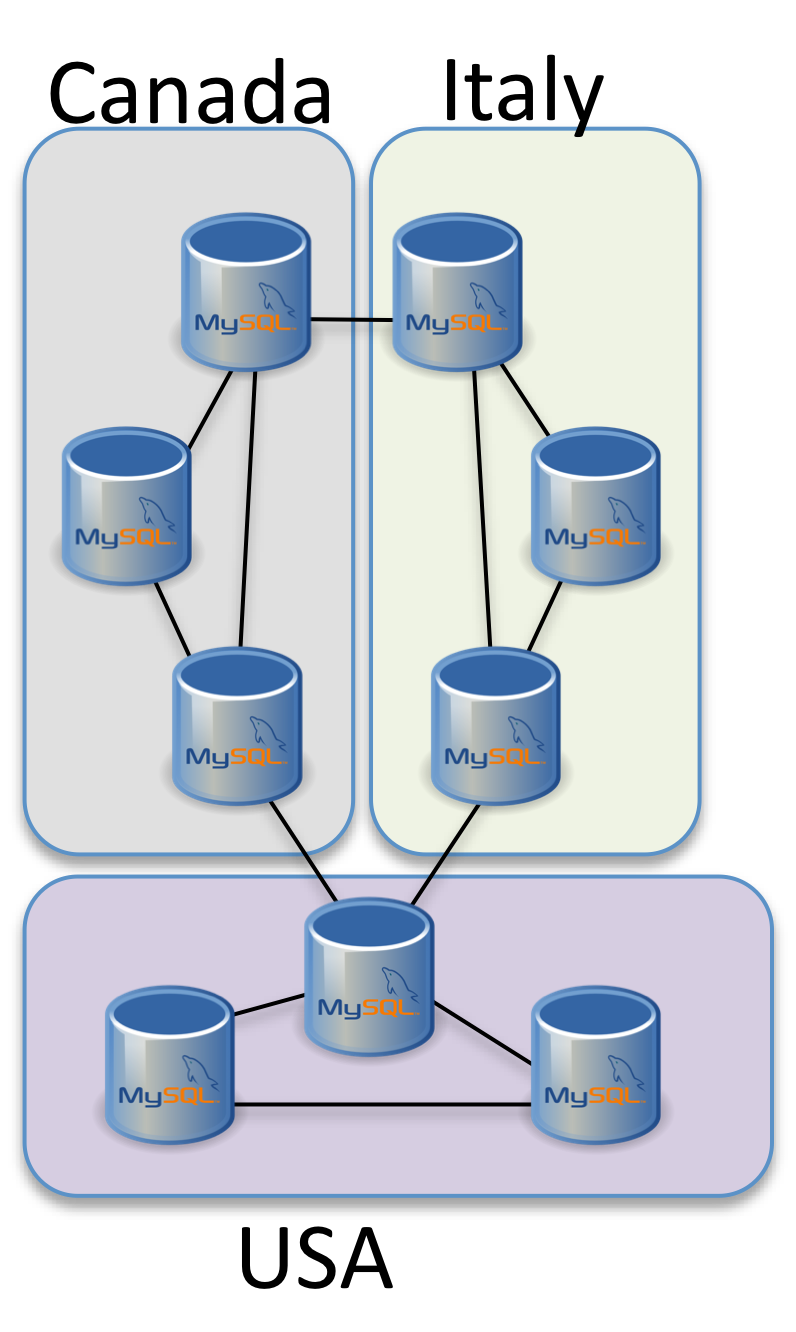 |
This looks easy, but I can tell you just right now that while the solution distributed on 3 geographic areas is going to work, the first one will have issue in case of crash.
To understand why, and to correctly design the segments you need to understand another important concept in Galera, which is the quorum calculation.
Generally, you will hear or read saying that Galera cluster should be deploy using an odd number of nodes to correctly manage the quorum calculation. This is not really true and not always needed if you understand how it works, and calculate it correctly.
Galera Cluster supports a weighted quorum, where each node can be assigned a weight in the 0 to 255 range, with which it will participate in quorum calculations.
The formula for the calculation is:
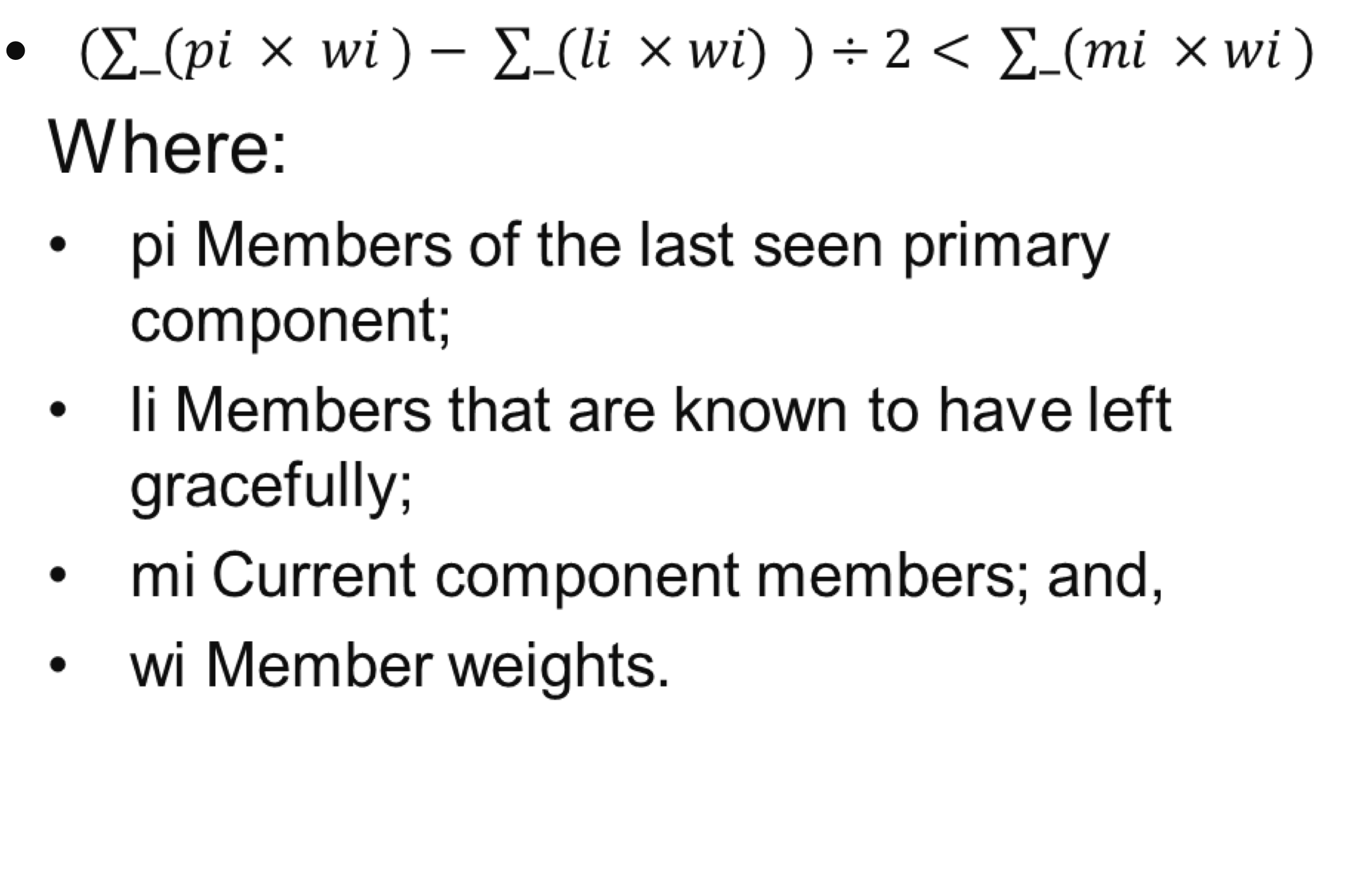
In short the weight sum of the previous view, excluding the node that had left gently, divided by two must be less than the sum of the weight of the current view.
Wait ... what is a view? A view is the logical grouping of nodes composing the cluster.
WSREP: view(view_id(PRIM,28b4b776,78)
memb {
28b4b776,1
79cc1886,1
8637105e,2
f218f33d,2
}
joined {} left {}
partitioned { b9aabaa5,1 <--- node is shutting down})
This is a view with ID 78 containing a group of nodes that is the PRIMARY Component, and having one node shutting down gently.
The View information is kept inside galera and on modification of the node(s) presence or access it is updated, the ID is incremented and the new view is compared with the previous following the formula describe above.
I think is quite clear, as such let see why I said that the first solution will not correctly work (by default), or more correctly will not work as you may expect.
So we have 6 nodes distributed cross 2 geo site each with different segment identifier.

If the network between the two sites will have issues and cluster cannot communicate the whole cluster will become NON-Primary:

As you can see if ONE of the two segment will become non reachable, the other will not have enough quorum to remain PRIMARY given 3 is not greater then 6/2 (3).
This is obviously the scenario in which all the weight is set as default to 1. This is also why it is recommended to use ODD nodes.
Just for clarity, see what happened if ONE node goes down and THEN the network crashes.



As you can see here the Final view has the quorum, and in that case the site in segment 1 will be able to stay up as PRIMARY, given 3 is greater then 5/2.
Anyhow back to our production – DR site how this can be set?
The first one is to decide that one of the two side will always win, like say production:


In this scenario the Segment 1 will always win, and to promote the DR to PRIMARY you must do it manually. That will work, but may be is not what we expect if we choose this solution for DR purposes.
The other option is to use a trick and add a witness like the arbitrator GARBD.
I don’t like the use of GARBD , never had, in the Codership documentation:
If one datacenter fails or loses WAN connection, the node that sees the arbitrator, and by extension sees clients, continues operation.
And
Even though Galera Arbitrator does not store data, it must see all replication traffic. Placing Galera Arbitrator in a location with poor network connectivity to the rest of the cluster may lead to poor cluster performance.
This means that if you use GARBD you will in any case have all the cost of the traffic but not the benefit of a real node. If this is not clear enough I will show you a simple case in which it may be more an issue then a solution.
In this scenario we will use GARBD and see what happen


We will have the quorum, but the point is… we may have it on both side, as such if the two segments will not be able to communicate, but are able to see the witness aka GARBD, each of them will think to be the good one. In short this is call split-brain, the nightmare of any DBA and SA.
As such the simple but real solution when using Galera also for DR, is to think at it as a geographically distributed cluster and add AT LEAST a 7th node, that will allow the cluster to calculate the quorum properly and in case two segments are temporary unable to connect. Not only the use of a third segment will work as man-in-the-middle passing messages from one segment to another, including the WriteSets.
So in case of real crash of ONE of the segment, the others will be able to keep going as PRIMARY without issue. On the other hand in case of crash of one of the network link, the cluster will be able to survive and distribute the data.
Conclusion
Use asynchronous replication to cover geographic distribution, may still be an option when the network or specific data access mode will prevent it. But the use of MySQ/Galera may be help you a lot in keep your data consistency under control and to manage HA more efficiently.
As such whatever need you may have (DR or distributed writes) use three different segments and sites, no matter if only for DR. This will improve the robustness of your solution.
MySQL/Galera is not only a good solution to have a geographical write distributed solution, but is also a robust solution in case of crash of one of the network link.
In that case the cluster will continue to work, but it may be in degraded state, given the third segment will have to forward the data to the other two nodes.
About that I have not yet perform extensive tests, but I will and post additional information.