A small thing that brings huge help.
The other day I was writing some code to process a very large amount of items coming from a social media API. My items were ending in a queue in MySQL and then needed to be processed and eventually moved.
The task was not so strange, but what I have to do is to develop a queue processor. Now when you need to process a queue you have two types of queue: static and dynamic.
The static comes in a batch of N number of items in a given time interval and is normally easier to process given you have a defined number of items that you can split in chunks and process in parallel.
The dynamic is… well... more challenging. One option is to wait to have a predefined number of items, and then process them as if they were a static queue.
But this approach is not very good, given it is possible that it will delay a lot the processing of an item for all the time it has to wait to reach the desired queue’s size.
The other possibility is to have the processing jobs work on a single item and not in chunk/batch. But, this is not optimal when given the chance to process a queue in batch to speed up the processing time.
My incoming queue is a bit unpredictable, a mix of fixed sizes and a few thousand coming sparse, without a clear interval. So I was there thinking on how to process this and already starting to design a quite complex mechanism to dynamically calculate the size of the possible chunks and the number of jobs, when…
An aside: some colleagues know my habit to read the whole MySQL manual, from A to Z, at least once a year. It's a way for me to review what is going on and sometimes to dig in more in some aspects. This normally also gives me a good level of confidence about new features and other changes on top of reading the release notes.
...When … looking at the documentation for something else, my attention was captured by:
“To avoid waiting for other transactions to release row locks, NOWAIT and SKIP LOCKED options may be used with SELECT ... FOR UPDATE or SELECT ... FOR SHARE locking read statements.”
Wait - what???
Let me dig in a bit:
“SKIP LOCKED. A locking read that uses SKIP LOCKED never waits to acquire a row lock. The query executes immediately, removing locked rows from the result set.”
Wow, how could I have missed that?
It was also not new but in MySQL 8.0.1, the milestone release. Having experience with Oracle, I knew what SKIP LOCKED does and how to use it. But I was really not aware that it was also available in MySQL.
In short, SKIP LOCKED allows you to lock a row (or set of them), bypassing the rows already locked by other transactions.
The classic example is:
# Session 1: mysql> CREATE TABLE t (i INT, PRIMARY KEY (i)) ENGINE = InnoDB; mysql> INSERT INTO t (i) VALUES(1),(2),(3); mysql> START TRANSACTION; mysql> SELECT * FROM t WHERE i = 2 FOR UPDATE; +---+ | i | +---+ | 2 | +---+ # Session 2: mysql> START TRANSACTION; mysql> SELECT * FROM t FOR UPDATE SKIP LOCKED; +---+ | i | +---+ | 1 | | 3 | +---+
But what is important for me is that given an N number of jobs running, I can bypass all the effort of calculating the dynamic chunks, given that using SKIP LOCKED that will happen as well, if in a different way.
All good, but what performance will I have using SKIP LOCK in comparison to the other two solutions?
I have run the following tests on my laptop, so not a real server, and used a fake queue processor I wrote on the fly to test the things you can find on GitHub here.
What I do is to create a table like this:
CREATE TABLE `jobs` ( `jobid` int unsigned NOT NULL AUTO_INCREMENT, `time_in` bigint NOT NULL, `time_out` bigint DEFAULT '0', `worked_time` bigint DEFAULT '0', `processer` int unsigned DEFAULT '0', `info` varchar(255) DEFAULT NULL, PRIMARY KEY (`jobid`), KEY `idx_time_in` (`time_in`,`time_out`), KEY `idx_time_out` (`time_out`,`time_in`), KEY `processer` (`processer`) ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci
Then I will do three different methods of processing:
- Simple process, reading and writing a row a time
- Use chunks to split my queue
- Use SKIP LOCKED
To clarify the difference existing between the 3 different way of processing the queue let us use 3 simple images:
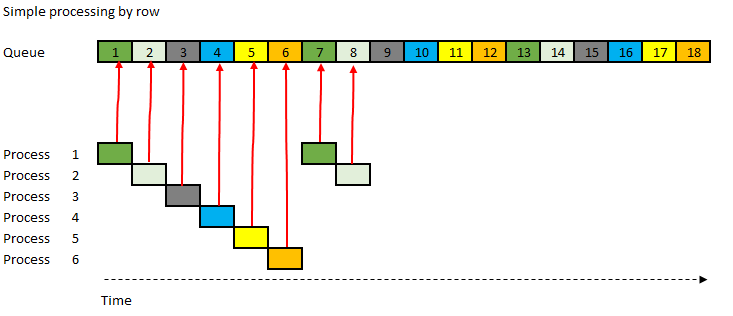
In simple processing each row represent a possible lock that the other processes must wait for.
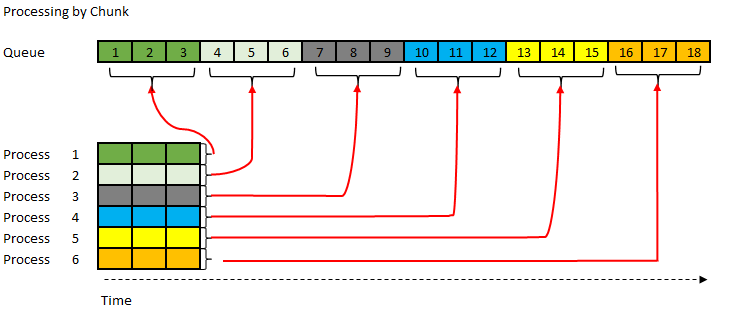
In chunk processing given each process knows what records to lock they can go in parallel.
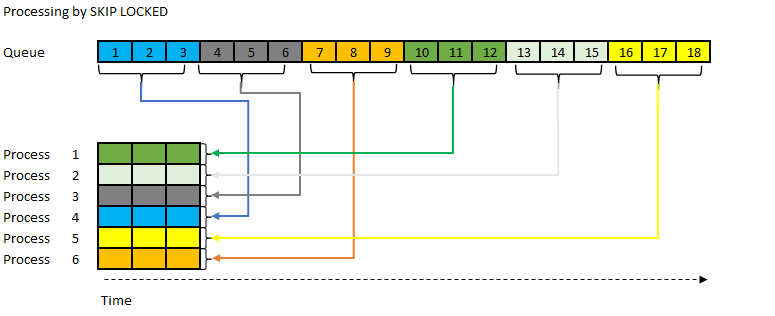
In SKIP LOCKED also if each process have no idea of what rows they need to lock, is enough to say the size of the chunk, and MySQL will return the records available.
I will repeat the tests for a static queue, and after for a dynamic queue for 20 seconds. Let's see what happens.
Test one - simple processing and static queue:
queue Processor report: ========================= Start Time = Tue Jul 28 13:28:25 CEST 2020 End Time = Tue Jul 28 13:28:31 CEST 2020 Total Time taken(ms) = 6325.0 Number of jobs = 5 Number of Items processed = 15000 Avg records proc time = 220308
Test 2 use the chunks and static queue
Chunk no loop -------------- queue Processor report: ========================= Start Time = Tue Jul 28 13:30:18 CEST 2020 End Time = Tue Jul 28 13:30:22 CEST 2020 Total Time taken(ms) = 4311.0 Number of jobs = 5 Number of Items processed = 15000 Avg records proc time = 391927
Test three - use SKIP LOCKED and static queue:
SKIP LOCK - no loop ------------------------ queue Processor report: ========================= Start Time = Tue Jul 28 13:32:07 CEST 2020 End Time = Tue Jul 28 13:32:11 CEST 2020 Total Time taken(ms) = 4311.0 Number of jobs = 5 Number of Items processed = 15000 Avg records proc time = 366812
So far, so good.
Time is almost the same (actually in this test, it's exactly the same), normally fluctuating a bit up and down by a few ms.
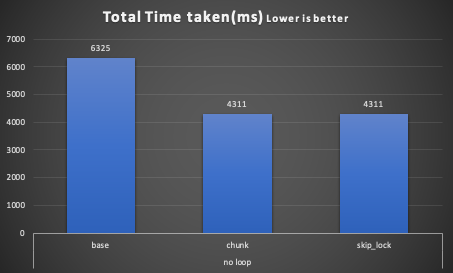
Average execution by commit fluctuates a bit:
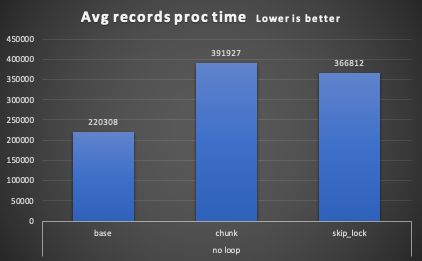
Here, the base execution is faster for the simple reason that the application is processing one record against a batch of records of the other two.
Now it is time to see what happens if instead of a static batch, I have a process that fills the queue constantly. If you want picture what will happen on each test, just imagine this:
- Some pipes will put water in a huge tank
- The base solution will try to empty the tank using a small glass of water but acting very fast at each run
- With Chunk it will wait for the water to reach a specific level, then will use a fixed-size bucket
- Using SKIP LOCK, it will constantly look at the tank and will choose the size of the bucket based on the quantity of the water present.
To simulate that, I will use five threads to write new items, five to process the queue, and will run the test for 20 seconds.
Here we will have some leftovers; that is how much water remains in the tank because the application was not emptied with the given bucket. We can say it is a way to measure the efficiency of the processing, where the optimal sees the tank empty.
Test one - simple processing and static queue:
Basic no loop -------------- queue Processor report: ========================= Start Time = Tue Jul 28 13:42:37 CEST 2020 End Time = Tue Jul 28 13:43:25 CEST 2020 Total Time taken(ms) = 48586.0 Number of jobs = 5 Number of Items processed = 15000 Total Loops executed (sum)= 85 Avg records proc time = 243400 Leftover +----------+------------+ | count(*) | max(jobId) | +----------+------------+ | 143863 | 225000 | +----------+------------+
Test 2 use the chunks and static queue:
Chunk no loop -------------- queue Processor report: ========================= Start Time = Tue Jul 28 13:44:56 CEST 2020 End Time = Tue Jul 28 13:45:44 CEST 2020 Total Time taken(ms) = 47946.0 Number of jobs = 5 Number of Items processed = 15000 Total Loops executed (sum)= 70 Avg records proc time = 363559 Leftover +----------+------------+ | count(*) | max(jobId) | +----------+------------+ | 53 | 195000 | +----------+------------+
Test 3 use SKIP LOCKED and static queue:
queue Processor report: ========================= Start Time = Tue Jul 28 14:46:45 CEST 2020 End Time = Tue Jul 28 14:47:32 CEST 2020 Total Time taken(ms) = 46324.0 Number of jobs = 5 Number of Items processed = 15000 Total Loops executed (sum)= 1528 Avg records proc time = 282658 Leftover +----------+------------+ | count(*) | max(jobId) | +----------+------------+ | 0 | NULL | +----------+------------+
Here, the scenario is a bit different than the one we had with the static queue.
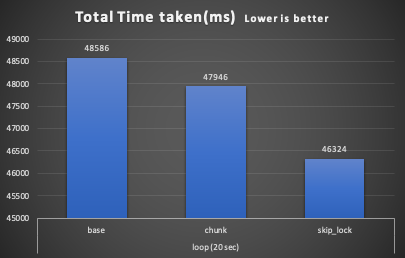
Here, the scenario is a bit different than the one we had with the static queue.
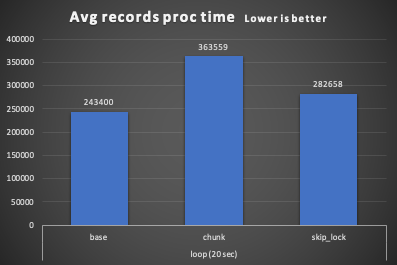
Record processing when comparing by chunk and SKIP LOCK is again more efficient in the second one. This is because it optimizes the size of the “bucket” and given that it can sometimes process fewer records per loop.
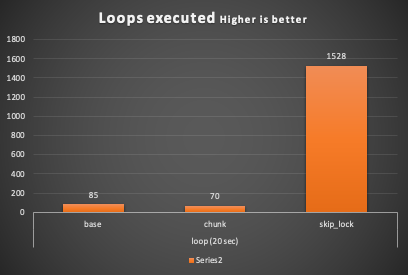
As we can see when using SKIP LOCK, the application was able to execute 1528 loops to process the queue against the 70 of the chunk and 85 of the basic approach.
In the end, the only one that was able to empty the tank was the solution with SKIP LOCK.
Conclusion
Processing queues can be simple when we need to process a fixed number of items, but if you need an adaptive approach, then the situation changes. You can find yourself writing quite complex algorithms to optimize the processing.
Using SKIP LOCK helps you in keeping the code/solution simple and move the burden of identifying the record to process onto the RDBMS.
SKIP LOCK is something that other technologies like Oracle-DB and Postgres already implemented, and their developer communities use.
MySQL implementation comes a bit later, and the option is not widely known or used in the developer’s community using MySQL, but it should.
Give it a try and let us know!
NOTE !!
SKIP LOCK is declared unsafe for statement replication, you MUST use ROW based replication if you use it.
References
MySQL 8.0 Hot Rows with NOWAIT and SKIP LOCKED
MySQL 8.0 Reference Manual: Locking Reads
{jcomments on}