Overview
Percona operator for MySQL (POM) :(https://www.percona.com/doc/kubernetes-operator-for-pxc/index.html) it’s aim is a special type of controller introduced to simplify complex deployments. The Operator extends the Kubernetes API with custom resources.
The Percona Operator for MySQL solution is using Percona Xtradb Cluster behind the hood to provide a highly available, resilient and scalable MySQL service in the Kubernetes space.
This solution comes with all the advantages/disadvantages provided by Kubernetes, plus with some advantages of its own like the capacity to scale reads on the nodes that are not Primary.
Of course there are some limitations like the way PXC handle DDLs, which may impact the service, but there is always a cost to pay to get something, expecting to have all for free is unreasonable.
In this context we need to talk and cover what is full read consistency in this solution and why it is important to understand the role it plays.
Stale Reads
When using Kubernetes we should talk about the service and not about the technology/product used to deliver such service.
In our case the Percona operator is there to deliver a MySQL service. We should then see that as a whole as a single object. To be more clear what we must consider is NOT the fact we have a cluster behind the service but that we have a service that to be resilient and highly available use a cluster.
We should not care If a node/pod goes down unless the service is discontinued.
What we have as a plus in the Percona operator for MySQL solution is a certain level of READ scalability. This achieved optimising the use of the non PRIMARY nodes, and instead having them sitting there applying only replicated data, the Percona Operator provides access to them to scale the reads.
But… there is always a BUT
Let us start with an image:
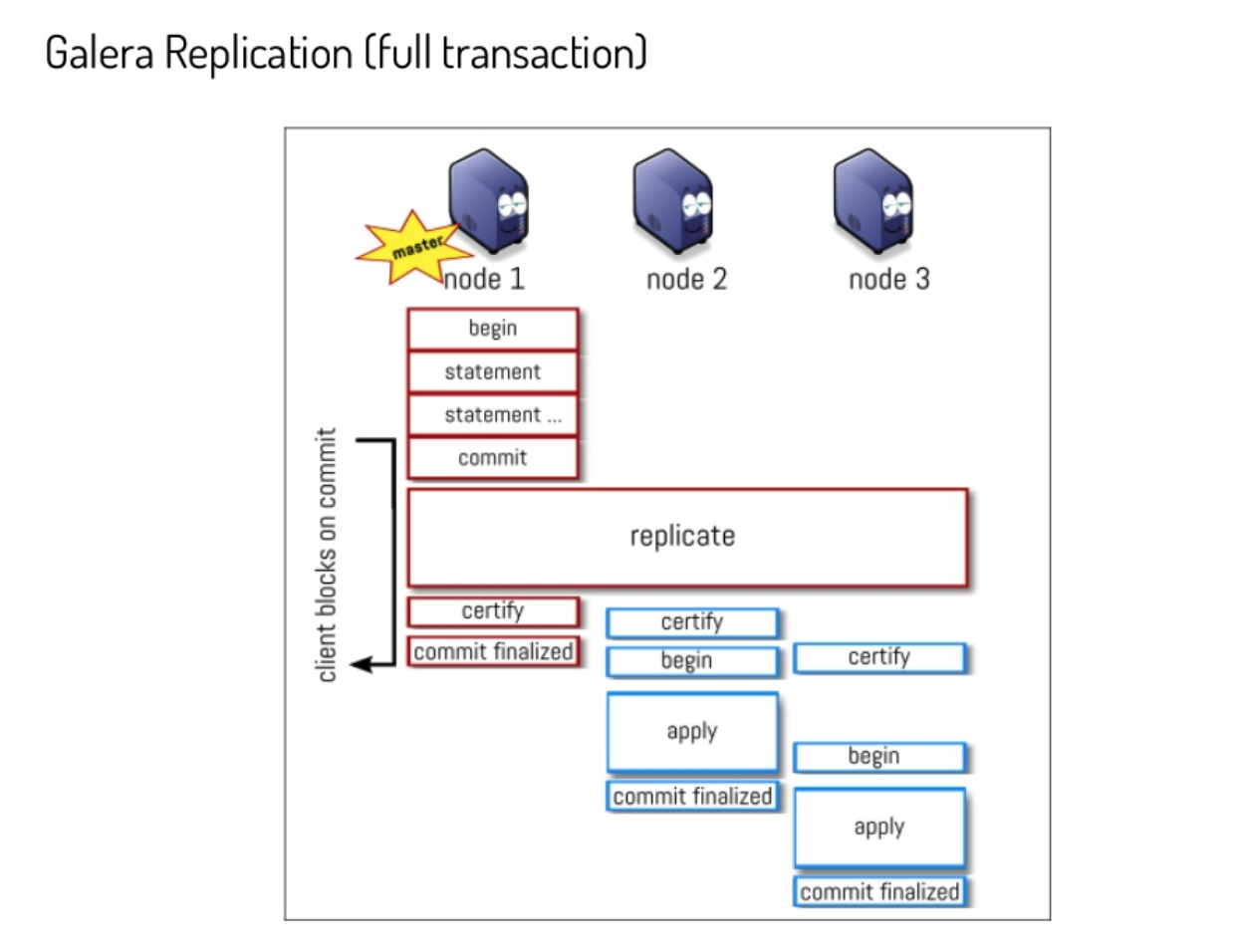
(https://www.slideshare.net/lefred.descamps/galera-replication-demystified-how-does-it-work) from Fred Descamps)
By design the apply and commit finalize in Galera (PXC) may have (and has) a delay between nodes.
This means that, if using defaults, applications may have inconsistent reads if trying to access the data from different nodes than the Primary.
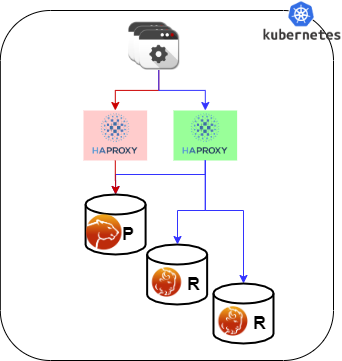
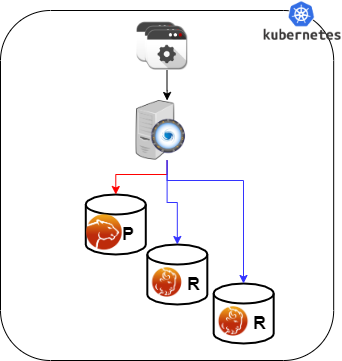
POM provides access using two different solutions:
- Using HAProxy (default)
- Using ProxySQL
 |
 |
When using HAProxy you will have 2 entry points:
- cluster1-haproxy, which will point to the Primary ONLY, for reads and writes. This is the default entry point for the applications to the MySQL database.
- cluster1-haproxy-replicas, which will point to all the 3 nodes and is supposed to be used for READS only. This is the PLUS you can use if your application has READ/WRITE separation.
![]()
Please note that at the moment there is nothing preventing application to use the cluster1-haproxy-replicas also for write, but that is dangerous and wrong because will generate a lot of certification conflicts and BF abort given it will distribute writes all over the cluster impacting on performance as well (and not giving you any write scaling):
[marcotusa@instance-1 ~]$ for i in `seq 1 100`; do mysql -h cluster1-haproxy-replicas -e "insert into test.iamwritingto values(null,@@hostname)";done +----------------+-------------+ | host | count(host) | +----------------+-------------+ | cluster1-pxc-1 | 34 | | cluster1-pxc-2 | 33 | | cluster1-pxc-0 | 33 | +----------------+-------------+
When using ProxySQL the entry point is a single one, but you may define query rules to automatically split the R/W requests coming from the application.
This is the preferred method when application has no way to separate the READS from the writes.
I have done a comparison of the two methods in POM here
Now, as mentioned above, by default PXC (any Galera base solution) comes with some relaxed settings, for performance purpose. This is normally fine in many standard cases, but if you use POM and use the PLUS of scaling reads using the second access point with HAproxy or Query Rules with Proxysql, you should NOT have stale reads, given the service must provide consistent data, as if you are acting on a single node.
To achieve that you can change the defaults and change the parameter in PXC wsrep_sync_wait.
When changing the parameter wsrep_sync_wait as explained in the documentation the node initiates a causality check, blocking incoming queries while it catches up with the cluster.
Once all data on the node receiving the READ request is commit_finalized, the node performs the read.
But this has a performance impact as said before.
What is the impact?
To test the performance impact I had used a cluster deployed in GKE, with this characteristics:
- 3 Main nodes n2-standard-8 (8 vCPUs, 32 GB memory)
- 1 App node n2-standard-8 (8 vCPUs, 32 GB memory)
- PXC pods using:
- 25GB of the 32 available
- 6 CPU of the 8 available
- HAProxy:
- 600m CPU
- 1GB RAM
- PMM agent
- 500m CPU
- 500 MB Ram
On The application node I used sysbench running two instances, one in r/w mode the other only reads. Finally to test stale read I used the stale read test from my test suite ( https://github.com/Tusamarco/testsuite) .
Given I was looking for results with moderate load I just used 68/96/128 threads per sysbench instance.
Results
Marco, did we have or not stale reads? Yes we did:
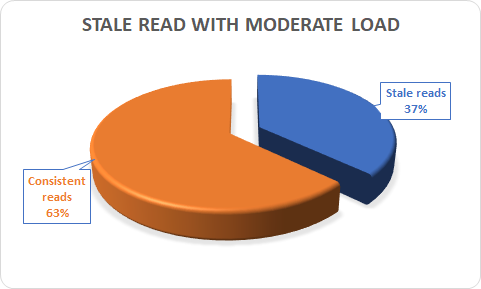
I had from 0 (with very light load) up to 37% stale reads with MODERATED load. Where moderated was the 128 threads sysbench running.
Setting wsrep_sync_wait=3 of course I had full consistency.
But I had performance loss:
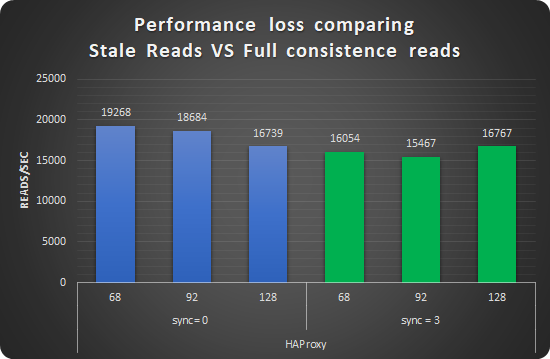
As you can see I had an average loss of 11% in case of READS
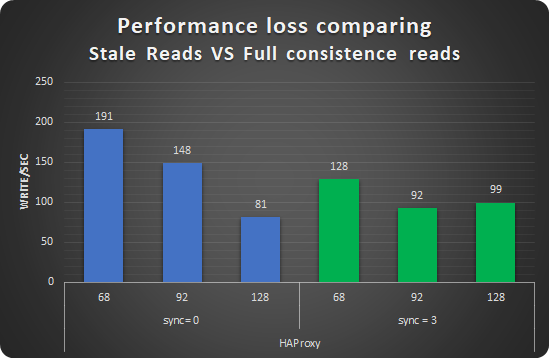
While for writes the average loss was the 16%.
Conclusions
At this point we need to stop and think about what is worth doing. If my application is READs heavy and READs scaling, it is probably worth enabling the full synchronicity given scaling on the additional node allows me to have a 2x or more READs.
If instead my application is write critical, probably losing also ~16% performance is not good.
Finally if my application is stale reads tolerant, I will just go with the defaults and get all the benefits without penalties.
Also keep in mind that POM is designed to offer a MySQL service so the state of the single node is not as critical as if you are using a default PXC installation, PODs are by nature ephemeral objects while service is resilient.
References
https://www.percona.com/doc/kubernetes-operator-for-pxc/index.html
https://github.com/Tusamarco/testsuite
https://en.wikipedia.org/wiki/Isolation_(database_systems)#Dirty_reads
https://galeracluster.com/library/documentation/mysql-wsrep-options.html#wsrep-sync-wait
https://www.slideshare.net/lefred.descamps/galera-replication-demystified-how-does-it-work