 Not long ago we had an internal discussion about security and how to enforce a stricter set of rules to prevent malicious acts, and block other undesired queries.
Not long ago we had an internal discussion about security and how to enforce a stricter set of rules to prevent malicious acts, and block other undesired queries.
ProxySQL comes up as a possible tool that could help us in achieving what we were looking for. Last year I had written how to use ProxySQL to stop a single query.
That approach may be good for few queries and as temporary solution. But what can we do when we really want to use ProxySQL as an SQL-based firewall? And more importantly, how to do it right?
First of all, let us define what “right” can be in this context.
For right I mean an approach that will allow us to have rules matching as specific as possible, and impacting the production system as least as possible.
To make this clearer, let us assume I have 3 schemas:
Shakila
World
Windmills
I want to have my firewall block/allow SQL access independently by each schema, user, eventually by source, and so on.
There are a few case where this is not realistic, like in SaaS setups where each schema represents a customer. In this case, the application will have exactly the same kind of SQL just pointing to different schemas depending the customer.
Using ProxySQL
Anyhow… ProxySQL allows you to manage query firewalling in a very simple and efficient way using the query rules.
In the mysql_query_rules table we can define a lot of important things and one of this is, to set our SQL firewall.
How?
Let us take a look to the mysql_query_rules table:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
rule_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, active INT CHECK (active IN (0,1)) NOT NULL DEFAULT 0, username VARCHAR, schemaname VARCHAR, flagIN INT NOT NULL DEFAULT 0, client_addr VARCHAR, proxy_addr VARCHAR, proxy_port INT, digest VARCHAR, match_digest VARCHAR, match_pattern VARCHAR, negate_match_pattern INT CHECK (negate_match_pattern IN (0,1)) NOT NULL DEFAULT 0, re_modifiers VARCHAR DEFAULT 'CASELESS', flagOUT INT, replace_pattern VARCHAR, destination_hostgroup INT DEFAULT NULL, cache_ttl INT CHECK(cache_ttl > 0), reconnect INT CHECK (reconnect IN (0,1)) DEFAULT NULL, timeout INT UNSIGNED, retries INT CHECK (retries>=0 AND retries <=1000), delay INT UNSIGNED, next_query_flagIN INT UNSIGNED, mirror_flagOUT INT UNSIGNED, mirror_hostgroup INT UNSIGNED, error_msg VARCHAR, OK_msg VARCHAR, sticky_conn INT CHECK (sticky_conn IN (0,1)), multiplex INT CHECK (multiplex IN (0,1,2)), log INT CHECK (log IN (0,1)), apply INT CHECK(apply IN (0,1)) NOT NULL DEFAULT 0, comment VARCHAR) |
We can define rules around almost everything: connection source, port, destination IP/Port, user, schema, SQL text, and any combination of them.
Given we may have a quite large set of queries to manage, I prefer to logically create “areas” around which add the rules to manage SQL access.
For instance, I may decide to allow a specific set of SELECTs to my schema windmills but nothing more.
Given that, I allocate the set of rule ids from 100 to 1100 to my schema, and add my rules in 3 groups.
- The exception that will bypass the firewall
- The blocking rule(s) [the firewall]
- The managing rules (post processing like sharding and so on)
There is a simple thing to keep in mind when you design rules for firewalling.
Do you need post processing of the query or not?
In the case you DON’T need post processing, the rule can simply apply and exit the QueryProcessor. That is probably the most common scenario and read/write split can be define in the exception rules assigning to the rule the desired HostGroup.
While if you need post-processing the rule MUST have apply=0 and the FLAGOUT must be define. That will allow you to have additional actions once the query is beyond the firewall.
An example is in case of sharding, where you need to process the sharding key/comment or whatever.
I will use the simple Firewall scenario, given this is the topic of the current article.
The rules
Let us start with the easy one, set 2, the blocking rule:
1 2 3 |
insert into mysql_query_rules (rule_id,username,schemaname,match_digest,error_msg,active,apply) values(1000,'pxc_test','windmills','.', 'You cannot pass.....I am a servant of the Secret Fire, wielder of the flame of Anor,. You cannot pass.',1, 1); |
In this query rule, I had defined the following:
- User connecting
- Schema name
- Any query
- Message to report
- Rule_id
That rule will block ANY query that will try to access the schema windmills from application user pxc_test.
Now in set 1, I will add all the rules I want let pass, will report here one only but all can be found in github here.
1 |
insert into mysql_query_rules (rule_id,proxy_port,username,destination_hostgroup, |
That is quite simple and straightforward but there is an important element that you must note.
In this rule, apply must have value of =1 always, to allow the query rule to bypass without further delay the firewall.
(Side Note: if you need post-processing, the flagout needs to have a value (like flagout=1000) and apply must be =0. That will allow the query to jump to the set 3, the managing rules.)
This is it, ProxySQL will go to the managing rules as soon as it finds a matching rule that will allow the application to access my database/schema, or it will exit if apply=1.
A graph can help to understand better:
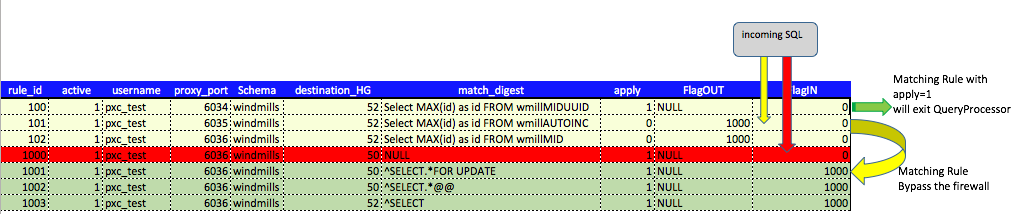
Rule set 3 will have the standard query rules to manage what to do with the incoming connection like sharding or redirecting SELECT FOR UPDATE and so on:
1 |
insert into mysql_query_rules (rule_id,proxy_port,schemaname,username,
|
Please note the presence of the flagin which matches the flagout above.
Setting rules, sometimes thousands of them can be very confusing. It is very important to plan correctly what should be in as excluding rule and what not. Do not rush, take your time and identify the queries you need to manage carefully.
Once more proxySQL can help us. Querying the table stats_mysql_query_digest will tell us exactly what queries were sent to ProxySQL, ie:
1 |
(admin@127.0.0.1) [main]>select hostgroup,schemaname,digest,digest_text,count_star
|
The above query shows us all the queries hitting the windmills schema. From there we can decide which queries we want to pass and which not.
1 2 3 4 5 6 7 8 9 |
>select hostgroup,schemaname,digest,digest_text,count_star |
Once we have our set done (check on github for an example), we are ready to check how our firewall works.
By default, I suggest you to keep all the exceptions (in set 1) with active=0, just to test the firewall.
For instance, my application will generate the following exception:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: |
Activating the rules, will instead allow your application to work as usual.
What the impact will be?
First,let us define the baseline, running the application without any rule blocking but only the r/w split (set 3).
Queries/sec global
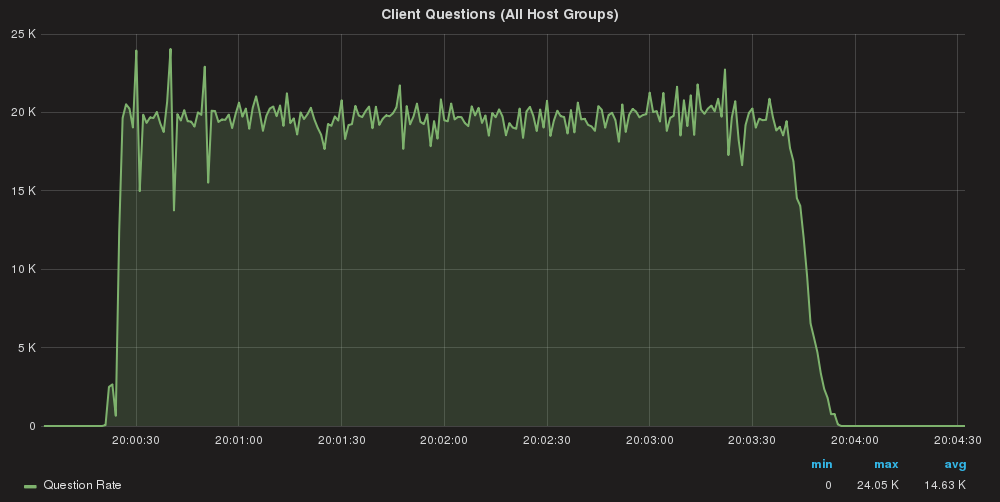
Using two application servers:
Server A: Total Execution time = 213
Server B: Total Execution time = 209
Queries/sec per server
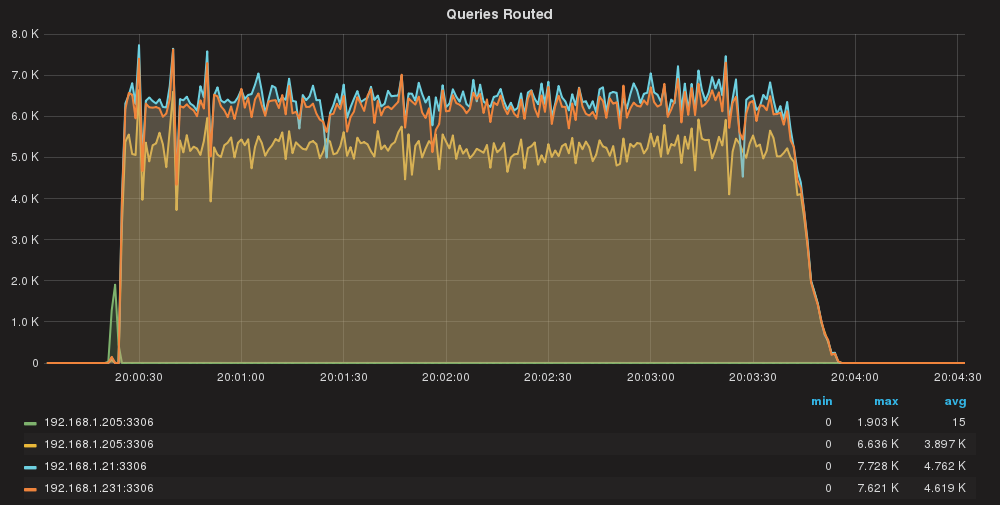
As we can see queries are almost equally distributed.
QueryProcessor time taken/Query processed total
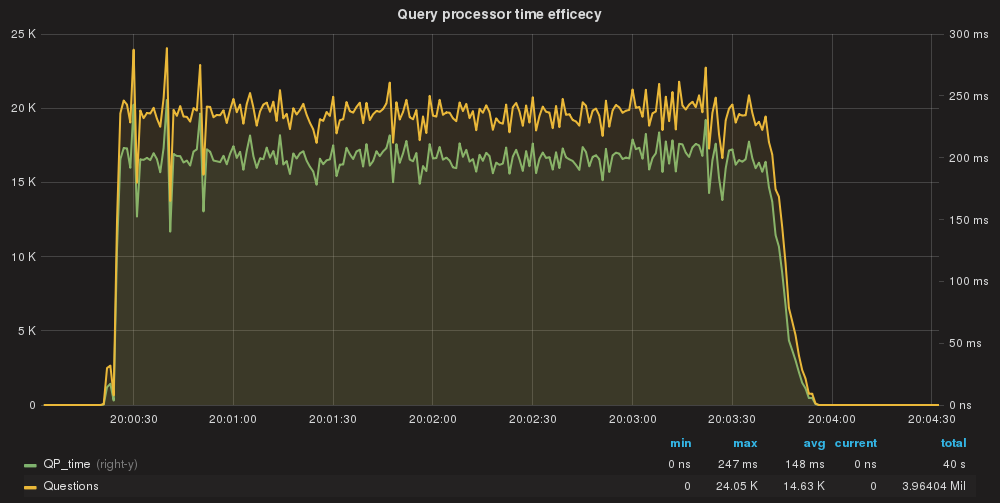
All queries are processed by QueryProcessor in ~148ms AVG (total)
QueryProcessor efficiency per query.
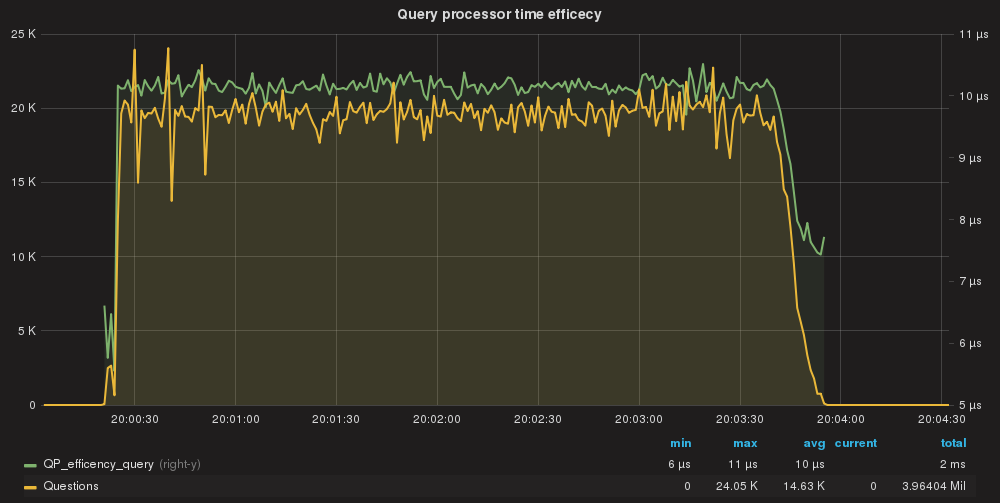
Single query cost is in nanoseconds avg 10 us.
Use match_digest
Once defined the baseline we can go ahead and activate all the rules using the match_digest.
Run the same tests again and… :
Queries/sec global
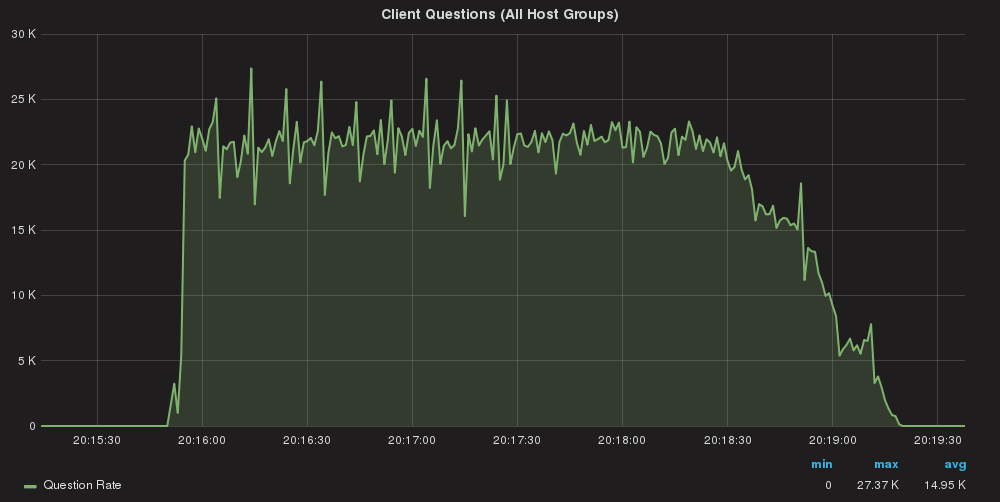
Using two application servers:
Server A: Total Execution time = 207
Server B: Total Execution time = 204
First of all, we can notice that the execution time did not increase. This is mainly because we have CPU cycles to use in the ProxySQL box.
Queries/sec per server
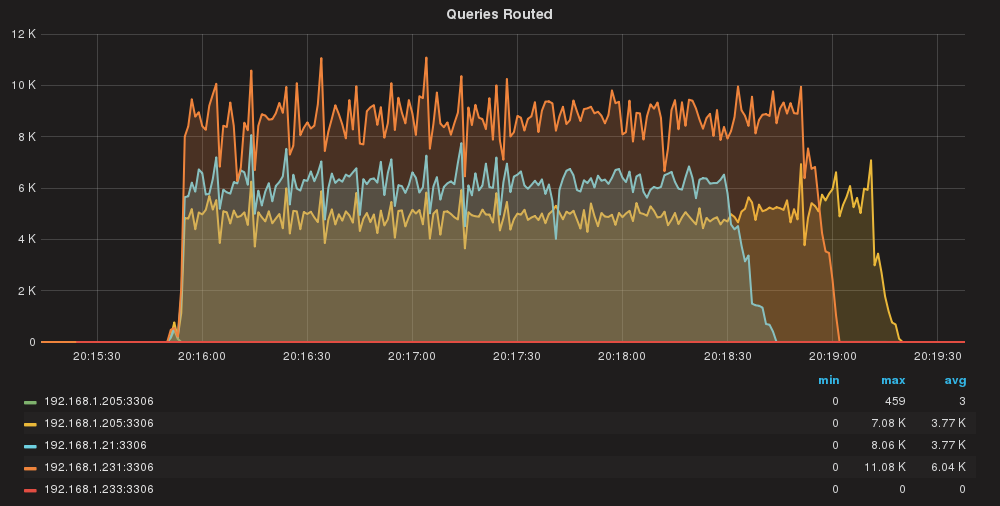
Here we have a bit of unbalance. We will investigate that in a separate session, but all in all, time/effort sounds ok.
QueryProcessor time taken/Query processed total
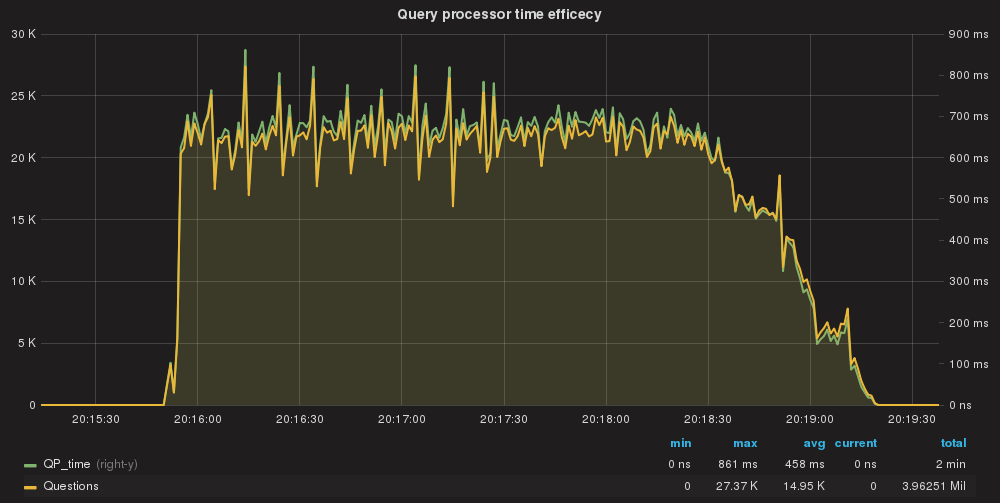
Here we have the first thing to notice. Comparing this to the baseline we had defined, we can see that using the rules as match_digest had significantly increase the execution time to 458ms.
QueryProcessor efficiency per query.
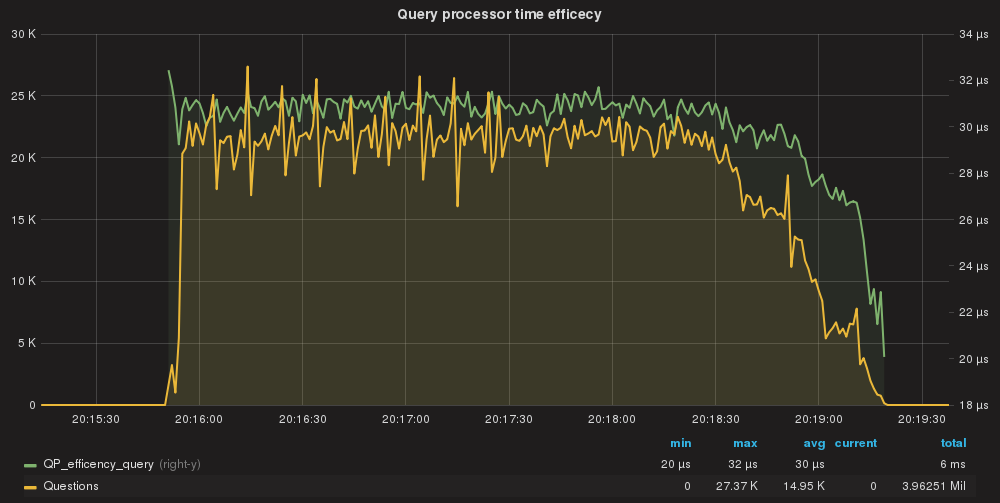
Notice that also if we are in the range of nanoseconds, the cost of processing the query is now 3 times that of the baseline. Not too much but if you add a stone to another stone and another stone and another stone … you end up building a huge wall.
So, what to do? Up to now we had seen that managing the firewall with ProxySQL is easy and it can be set at very detailed level, but the cost may not be what we expect it to be.
What can be done? Use DIGEST instead.
The secret is to not use match_digest, which implies interpretation of the string, but to use the DIGEST of the query, which is calculated ahead and remains constant for that query.
Let us see what will be if we run the same load using DIGEST in the MYSQL_QUERY_RULES table.
Queries/sec global
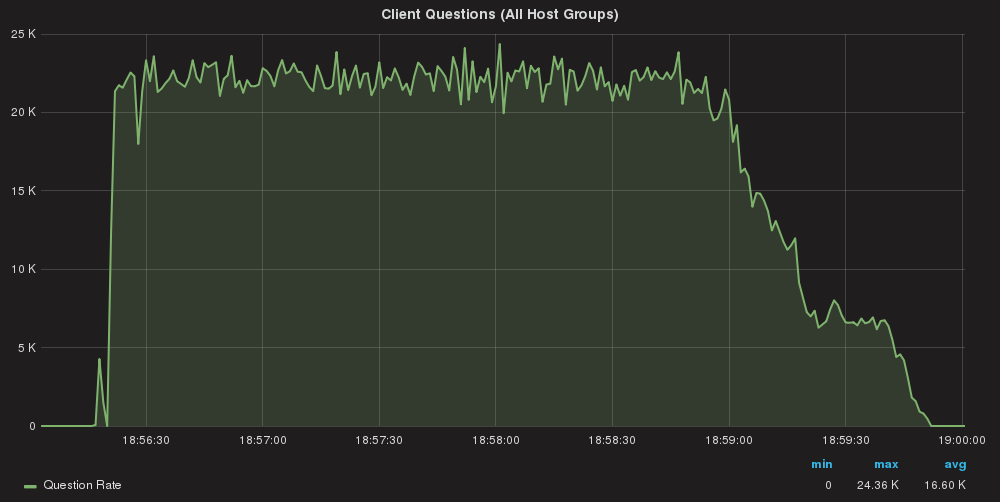
Using two application servers:
Server A: Total Execution time = 213
Server B: Total Execution time = 209
No, this is not an issue with cut and paste. I had more or less the same execution time as if without rules, at the seconds; different millisecond though.
Queries/sec per server
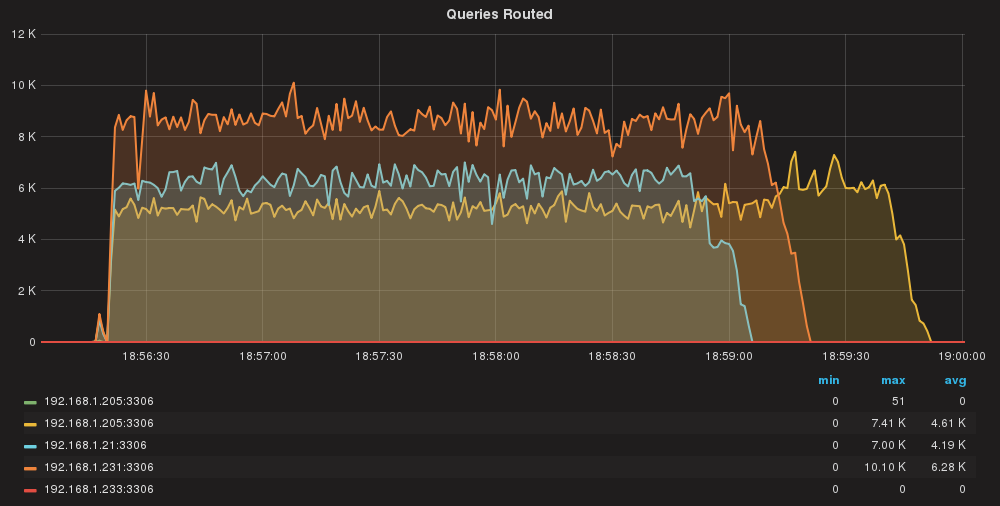
Again, here some unbalance, but minor thing.
QueryProcessor time taken/Query processed total
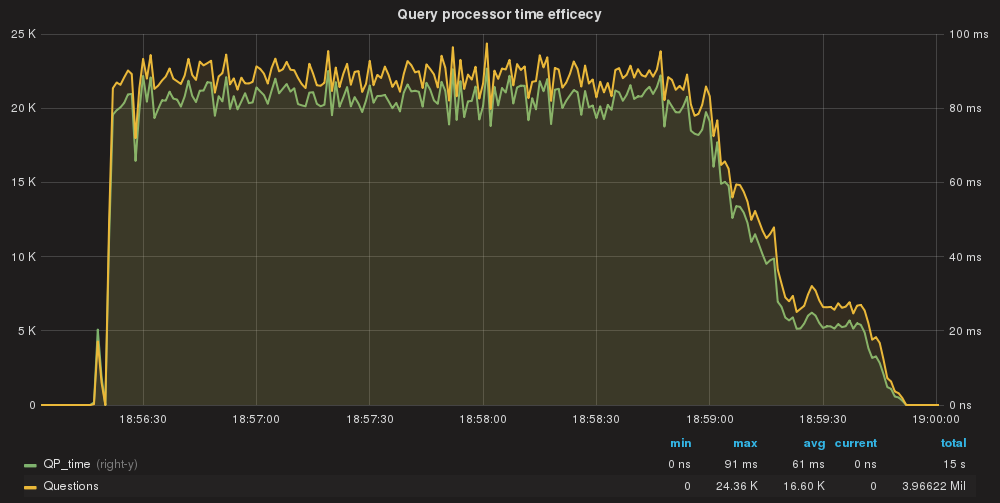
And we go down as we should to 61ms as execution of all queries. Note that we improve the efficiency of the Query Processor from 148ms AVG to 61ms AVG.
Why? Because our rules using the DIGEST also have the instructions for read/write split, so request can exit the Query Processor with all the information required at this stage; more efficient.
QueryProcessor efficiency per query.
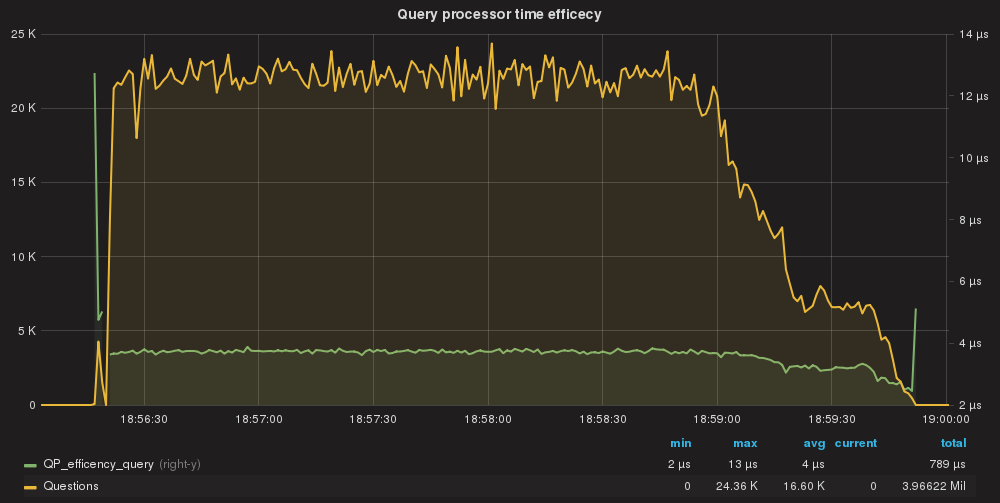
Finally using the DIGEST, the cost for query drops to 4us which is … LOW!
That’s it! ProxySQL using the DIGEST field from mysql_query_rules, will perform much better, given that it will not need to analyze the whole SQL string with regular expression, but it will just match the DIGEST.
Conclusions
ProxySQL can be effectively used as an SQL firewall, but some best practices should be taken in to consideration.
First of all, try to use specific rules, and be specific on what should be filtered/allowed. Use filter by schema or user or IP/port or combination of them.
Always try to avoid match_digest and use digest instead. That will allow ProxySQL to bypass the call to the regularExp lib and it will be by far more efficient.
Use stats_mysql_query_digest to identify the correct DIGEST.
Regarding this, it would be nice to have an GUI interface that will allow us to manage these rules; that would make the usage of the ProxySQL much easier, and the maintenance/creation of rule_chains friendlier.