Achieving Consistent Read and High Availability with Percona XtraDB Cluster 8.0 (Part 2)
Now that we had seen how to setup our environment with PXC8 is time to see how our setup will behave and what can be done in case of issues.
We will now analyse the following common situations:
- Put a node in maintenance or remove a node and insert it back
- node crash
- network failure
- proxysql node crash
The following tests are done using a java application connecting using straight JDBC connection and no connection pooling. I choose to use that more than a benchmarking tool such as sysbench because I was looking for something as close to a real application more than a benchmark. Especially I was interested in having dependencies cross requests and real data retrieve and error management.
As soon as we start the schedule script, the script checks the nodes and identify that we have writer_is_also_reader=0 so it removes the entry for the current writer
2020/07/03 06:43:50.130:[INFO] Writer is also reader disabled removing node from reader Hostgroup 192.168.1.5;3306;201;5000 Retry #1
2020/07/03 06:43:50.138:[WARN] DELETE node:192.168.1.5;3306;201;5000 SQL: DELETE from mysql_servers WHERE hostgroup_id=201 AND hostname='192.168.1.5' AND port='3306'
2020/07/03 06:43:50.143:[INFO] END EXECUTION Total Time(ms):277.705907821655
Test 1 Put a node in maintenance
PXC has a very useful feature pxc_maint_mode to deal with maintenance and to notify applications and midlevel architectural blocks (such as ProxySQL) that a node is going to be under maintenance.
With pxc_maint_mode you can specifies the maintenance mode for taking a node down without adjusting settings in ProxySQL.
The following values are available:
DISABLED: This is the default state that tells ProxySQL to route traffic to the node as usual.SHUTDOWN: This state is set automatically when you initiate node shutdown.MAINTENANCE: You can manually change to this state if you need to perform maintenance on a node without shutting it down.
The First test is to put a reader in maintenance and put it back.
current scenario in ProxySQL:
+--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+ | 10000 | 200 | 192.168.1.5 | ONLINE | 2 | 3 | 5 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | ONLINE | 2 | 15 | 17 | 0 | 17 | | 10000 | 201 | 192.168.1.6 | ONLINE | 0 | 12 | 12 | 0 | 12 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0. | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+
Putting down the 192.168.1.6 node:
(root localhost) [(none)]>set global pxc_maint_mode=maintenance;
Query OK, 0 rows affected (10.00 sec)
+--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+ | 10000 | 200 | 192.168.1.5 | ONLINE | 0 | 5 | 5 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | ONLINE | 1 | 15 | 17 | 0 | 17 | | 10000 | 201 | 192.168.1.6 | OFFLINE_SOFT | 0 | 0 | 12 | 0 | 12 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+
Node is in OFFLINE_SOFT as such it will allow any existing connection to finish while not accepting any new.
We can wait for running connection to end, then do whatever kind of maintenance we need without affecting our production.
Once done we can move the node back:
[(none)]>set global pxc_maint_mode=disabled;
Query OK, 0 rows affected (0.00 sec)
In the script log we will see that the node is identify as ready to be put back:
2020/07/03 06:58:23.871:[INFO] Evaluate nodes state 192.168.1.6;3306;201;1000 Retry #1
2020/07/03 06:58:23.882:[WARN] Move node:192.168.1.6;3306;201;1000 SQL: UPDATE mysql_servers SET status='ONLINE' WHERE hostgroup_id=201 AND hostname='192.168.1.6' AND port='3306'
2020/07/03 06:58:23.887:[INFO] END EXECUTION Total Time(ms):265.045881271362
In all this we never had a moment of service interruption.
The above test was the easy one.
Let us now see what happens if we put the writer in maintenance.
This is a much more impacting action, given the node is accepting write transactions and is in single mode.
Ler us put the writer 192.168.1.5 in maintenance:
set global pxc_maint_mode=maintenance;
Query OK, 0 rows affected (10.00 sec)
And in few seconds:
+--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+ | 999 | 200 | 192.168.1.6 | ONLINE | 3 | 2 | 5 | 0 | 5 | | 10000 | 200 | 192.168.1.5 | OFFLINE_SOFT | 0 | 0 | 5 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | ONLINE | 4 | 12 | 17 | 0 | 17 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+
What happened?
In the script log:
...
2020/07/03 08:11:22.110:[INFO] END EXECUTION Total Time(ms):231.402158737183
2020/07/03 08:11:24.299:[WARN] PXC maintenance on single writer, is asking for failover. Fail-over in action Using Method = 1
2020/07/03 08:11:24.307:[WARN] Move node:192.168.1.5;3306;200;3020 SQL: UPDATE mysql_servers SET status='OFFLINE_SOFT' WHERE hostgroup_id=200 AND hostname='192.168.1.5' AND port='3306'
2020/07/03 08:11:24.313:[INFO] Special Backup - Group found! I am electing a node to writer following the indications
This Node Try to become the new WRITER for HG 200 Server details: 192.168.1.6:3306:HG8200
2020/07/03 08:11:24.313:[INFO] This Node Try to become a WRITER promoting to HG 200 192.168.1.6:3306:HG 8200
2020/07/03 08:11:24.313:[WARN] DELETE from writer group as: SQL:DELETE from mysql_servers where hostgroup_id in (200,9200) AND STATUS = 'ONLINE'
2020/07/03 08:11:24.720:[WARN] Move node:192.168.1.6:33069992000 SQL:INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.1.6',200,3306,999,2000);
2020/07/03 08:11:24.720:[WARN] !!!! FAILOVER !!!!!
Cluster was without WRITER I have try to restore service promoting a node
2020/07/03 08:11:24.720:[INFO] END EXECUTION Total Time(ms):685.911178588867
...
The script identify the need to shift production to another node.
It set the current writer as offline in the staging environment and identify which node from the special group 8000 is the appropriate replacement.
Then push all the changes to runtime
All is done in ~700 ms, so the whole process takes less then a second and the production was not impacted.
Test 2 writer node crash
Note: In the text below MySQL is set to work on CEST while system is EDT.
This is of course a much more impacting scenario, we need to keep in to account not only the the situation of the node in ProxySQL, but the need for PXC to rebuild the Primary view getting quorum etc..
Initial picture:
+--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+ | 999 | 200 | 192.168.1.6 | ONLINE | 3 | 2 | 5 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | ONLINE | 4 | 12 | 17 | 0 | 17 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+--------------+----------+----------+--------+---------+-------------+/pre>
Abruptly killing the writer with kill -9 signal:
[root@galera1h1n6 gal8_2]# ps aux|grep gal8_2
root 5265 0.0 0.0 113452 876 ? S Jun26 0:00 /bin/sh /opt/mysql_templates/PXC8/bin/mysqld_safe --defaults-file=/opt/mysql_instances/gal8_2/my.cnf
mysql 8745 7.7 72.9 9355104 5771476 ? Sl Jun26 882:54 /opt/mysql_templates/PXC8/bin/mysqld
PXC cluster start to identify the issue:
2020-07-04T10:05:41.011531Z 0 [Note] [MY-000000] [Galera] (27260297, 'tcp://192.168.1.5:4567') turning message relay requesting on, nonlive peers: tcp://192.168.1.6:4567
And script as well:
2020/07/04 06:05:41.000:[ERROR] Cannot connect to DBI:mysql:host=192.168.1.6;port=3306 as monitor 2020/07/04 06:05:41.001:[ERROR] Node is not responding setting it as SHUNNED (ProxySQL bug - #2658)192.168.1.6:3306:HG200 2020/07/04 06:05:41.052:[WARN] PXC maintenance on single writer, is asking for failover. Fail-over in action Using Method = 1 2020/07/04 06:05:41.061:[INFO] Special Backup - Group found! I am electing a node to writer following the indications This Node Try to become the new WRITER for HG 200 Server details: 192.168.1.5:3306:HG8200 2020/07/04 06:05:41.062:[INFO] This Node Try to become a WRITER promoting to HG 200 192.168.1.5:3306:HG 8200 2020/07/04 06:05:41.062:[WARN] DELETE from writer group as: SQL:DELETE from mysql_servers where hostgroup_id in (200,9200) AND STATUS = 'ONLINE'
As said there is also the need from the cluster to rebuild the cluster view and get a quorum (see below):
2020-07-04T10:05:45.685154Z 0 [Note] [MY-000000] [Galera] Current view of cluster as seen by this node
view (view_id(PRIM,27260297,16)
memb {
27260297,1
7e4d3144,1
}
joined {
}
left {
}
partitioned {
3eb94984,1
}
)
As soon as the view is available the script can perform the failover:
2020/07/04 06:05:46.318:[WARN] Move node:192.168.1.5:330610002000 SQL:INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.1.5',200,3306,1000,2000);
2020/07/04 06:05:46.318:[WARN] !!!! FAILOVER !!!!!
Cluster was without WRITER I have try to restore service promoting a node
2020/07/04 06:05:46.318:[INFO] END EXECUTION Total Time(ms):5551.42211914062
the whole exercise takes 5 seconds.
Which for a server crash is not bad at all.
In my case given the Java application was design to deal with minimal service interruption with retry loop, I did not had any error, but this depends on how you had wrote the application layer.
+--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | 1000 | 200 | 192.168.1.5 | ONLINE | 0 | 4 | 5 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | ONLINE | 0 | 26 | 30 | 0 | 28 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | SHUNNED | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | SHUNNED | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+
Node also if SHUNNED in the special groups will be normally managed and in the need put ONLINE.
Crash of a reader
Let us now do the same with a reader
[root galera1h1n7 gal8_3]# date; kill -9 5259 8739
Sat Jul 4 06:43:46 EDT 2020
The script will fail to connect :
2020/07/04 06:43:46.923:[ERROR] Cannot connect to DBI:mysql:host=192.168.1.7;port=3306 as monitor 2020/07/04 06:43:46.923:[ERROR] Node is not responding setting it as SHUNNED (ProxySQL bug - #2658)192.168.1.7:3306:HG8201 2020-07-04T10:43:47.998377Z 0 [Note] [MY-000000] [Galera] (27260297, 'tcp://192.168.1.5:4567') reconnecting to 7e4d3144 (tcp://192.168.1.7:4567), attempt 0
The node is internally SHUNNED by the script given not accessible, while waiting for ProxySQL to take action and shun the node. All reads request are managed by ProxySQL.
The final picture will be:
+--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | 1000 | 200 | 192.168.1.5 | ONLINE | 0 | 5 | 6 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | SHUNNED | 0 | 0 | 30 | 98 | 28 | | 1000 | 201 | 192.168.1.6 | ONLINE | 1 | 24 | 25 | 0 | 25 | | 998 | 8200 | 192.168.1.7 | SHUNNED | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | SHUNNED | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+
No service interruption from the read side thanks to ProxySQL.
Test 3 network failure
Network failures are always tricky, they can happen as a simple single instance, or for a large but unpredictable window of time.
Network can have a slow down first such that the node affect the whole cluster, then fully resolve themselves, leaving you with very limited data to understand what and why that happens.
Given that is important to try to take action to limit negative effects as much as possible.
That level of actions are above the scope of a scheduler Script, who is in charge only of the layout of the nodes.
Given that what it should do is not to solve the possible impact at PXC level but reduce the possible confusion in distributing the traffic with ProxySQL.
The initial picture is:
+--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | 1000 | 200 | 192.168.1.5 | ONLINE | 0 | 5 | 6 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | SHUNNED | 0 | 0 | 30 | 98 | 28 | | 1000 | 201 | 192.168.1.6 | ONLINE | 1 | 24 | 25 | 0 | 25 | | 998 | 8200 | 192.168.1.7 | SHUNNED | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | SHUNNED | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+
On node 192.168.1.5 I will stop the network interface.
enp0s8: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.5 netmask 255.255.255.0 broadcast 192.168.1.255
[vagrant galera1h1n5 ~]$ date;sudo ifdown enp0s8
Sat Jul 4 13:20:32 EDT 2020
Device 'enp0s8' successfully disconnected.
As soon as I stop it, the PXC cluster identify the node is not reachable:
2020-07-04T17:20:35.980786Z 0 [Note] [MY-000000] [Galera] (7e4d3144, 'tcp://192.168.1.7:4567') connection to peer 27260297 with addr tcp://192.168.1.5:4567 timed out, no messages seen in PT3S (gmcast.peer_timeout)
The script is running and must timeout the attempt to connect (6 seconds), and fencing other process to start:
2020/07/04 13:20:36.729:[ERROR] Another process is running using the same HostGroup and settings,
Or orphan pid file. check in /tmp/proxysql_galera_check_200_W_201_R.pid
2020/07/04 13:20:38.806:[ERROR] Another process is running using the same HostGroup and settings,
Or orphan pid file. check in /tmp/proxysql_galera_check_200_W_201_R.pid
Finally script node connection time out and failover starts
2020/07/04 13:20:40.699:[ERROR] Cannot connect to DBI:mysql:host=192.168.1.5;port=3306;mysql_connect_timeout=6 as monitor
2020/07/04 13:20:40.699:[ERROR] Node is not responding setting it as SHUNNED (internally) (ProxySQL bug - #2658)192.168.1.5:3306:HG200
2020/07/04 13:20:40.804:[WARN] Fail-over in action Using Method = 1
2020/07/04 13:20:40.805:[INFO] Special Backup - Group found! I am electing a node to writer following the indications
This Node Try to become the new WRITER for HG 200 Server details: 192.168.1.6:3306:HG8200
2020/07/04 13:20:40.805:[INFO] This Node Try to become a WRITER promoting to HG 200 192.168.1.6:3306:HG 8200
2020/07/04 13:20:40.805:[WARN] DELETE from writer group as: SQL:DELETE from mysql_servers where hostgroup_id in (200,9200) AND STATUS = 'ONLINE'
2020/07/04 13:20:42.622:[WARN] Move node:192.168.1.6:33069992000 SQL:INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_connections) VALUES ('192.168.1.6',200,3306,999,2000);
2020/07/04 13:20:42.623:[WARN] !!!! FAILOVER !!!!!
Cluster was without WRITER I have try to restore service promoting a node
2020/07/04 13:20:42.623:[INFO] END EXECUTION Total Time(ms):7983.0858707428
Script does failover due to network in 7 seconds, 10 seconds from network issue
final picture:
+--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+ | 999 | 200 | 192.168.1.6 | ONLINE | 0 | 5 | 5 | 0 | 5 | | 10000 | 201 | 192.168.1.7 | ONLINE | 3 | 16 | 60 | 721 | 28 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | SHUNNED | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | SHUNNED | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+---------+----------+----------+--------+---------+-------------+
Given the level of complexity a network failure brings, I think this is a pretty good results, also if it will be inevitable to have some application errors given the connection was on the fly, and for that there is no way to prevent, except re-run the whole transaction.
Test 4 ProxySQL node crash
Last test is what happen if a proxysql node crash? We have set a VIP that we use to connect to ProxySQL (192.168.1.194), and set Keepalived to deal with the move of the VIP cross nodes will that be efficient enough?
Let us try killing one of the ProxySQL node.
Picture before:
+--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+ | 999 | 200 | 192.168.1.6 | ONLINE | 3 | 1 | 4 | 0 | 4 | | 10000 | 201 | 192.168.1.7 | ONLINE | 3 | 7 | 10 | 0 | 10 | | 1000 | 201 | 192.168.1.5 | ONLINE | 0 | 2 | 2 | 0 | 2 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+
I connect on the current Proxy node that is in charge of the `vip and:
[root proxy1 proxysql]# date;kill -9 24890 24891
Sat Jul 4 14:02:29 EDT 2020
In the system log of the next in the chain Proxy server (different machine), Keepalived identify the node is down and swap the VIP:
Jul 4 14:02:31 proxy2 Keepalived_vrrp[6691]: VRRP_Instance(VI_01) forcing a new MASTER election
Jul 4 14:02:32 proxy2 Keepalived_vrrp[6691]: VRRP_Instance(VI_01) Transition to MASTER STATE
Jul 4 14:02:33 proxy2 Keepalived_vrrp[6691]: VRRP_Instance(VI_01) Entering MASTER STATE
Jul 4 14:02:33 proxy2 Keepalived_vrrp[6691]: VRRP_Instance(VI_01) setting protocol VIPs.
Jul 4 14:02:33 proxy2 Keepalived_vrrp[6691]: Sending gratuitous ARP on enp0s8 for 192.168.1.194
Jul 4 14:02:33 proxy2 Keepalived_vrrp[6691]: VRRP_Instance(VI_01) Sending/queueing gratuitous ARPs on enp0s8 for 192.168.1.194
Jul 4 14:02:33 proxy2 Keepalived_vrrp[6691]: Sending gratuitous ARP on enp0s8 for 192.168.1.194
Jul 4 14:02:33 proxy2 Keepalived_vrrp[6691]: Sending gratuitous ARP on enp0s8 for 192.168.1.194
Application identify few connection that were close unexpectedly and try to restore them:
20/07/04 14:02:33 ERROR [ACTIONS2]: ##### Connection was closed at server side unexpectedly. I will try to recover it
20/07/04 14:02:33 ERROR [ACTIONS2]: ##### Connection was closed at server side unexpectedly. I will try to recover it
20/07/04 14:02:33 ERROR [ACTIONS2]: ##### Connection was closed at server side unexpectedly. I will try to recover it
20/07/04 14:02:33 ERROR [ACTIONS2]: ##### Connection was closed at server side unexpectedly. I will try to recover it
So in few seconds ProxySQL on the Proxy2 node is up and running able to manage the traffic:
+--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+ | weight | hostgroup_id | srv_host | status | ConnUsed | ConnFree | ConnOK | ConnERR | MaxConnUsed | +--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+ | 999 | 200 | 192.168.1.6 | ONLINE | 0 | 6 | 6 | 0 | 6 | | 10000 | 201 | 192.168.1.7 | ONLINE | 3 | 29 | 32 | 0 | 32 | | 1000 | 201 | 192.168.1.5 | ONLINE | 0 | 2 | 2 | 0 | 2 | | 998 | 8200 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 999 | 8200 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8200 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.7 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.6 | ONLINE | 0 | 0 | 0 | 0 | 0 | | 1000 | 8201 | 192.168.1.5 | ONLINE | 0 | 0 | 0 | 0 | 0 | +--------+--------------+-------------+--------+----------+----------+--------+---------+-------------+
Full failover done in 4 Seconds !!!!
Also this to me sounds a quite good achievement.
Conclusions
We can achieve very highly customisable setup with the use of the scheduler+script in ProxySQL.
The flexibility we get is such that we can create a very high available solution without the need to accept compromises impose by native galera support.
All this without reducing the efficiency of the solution.
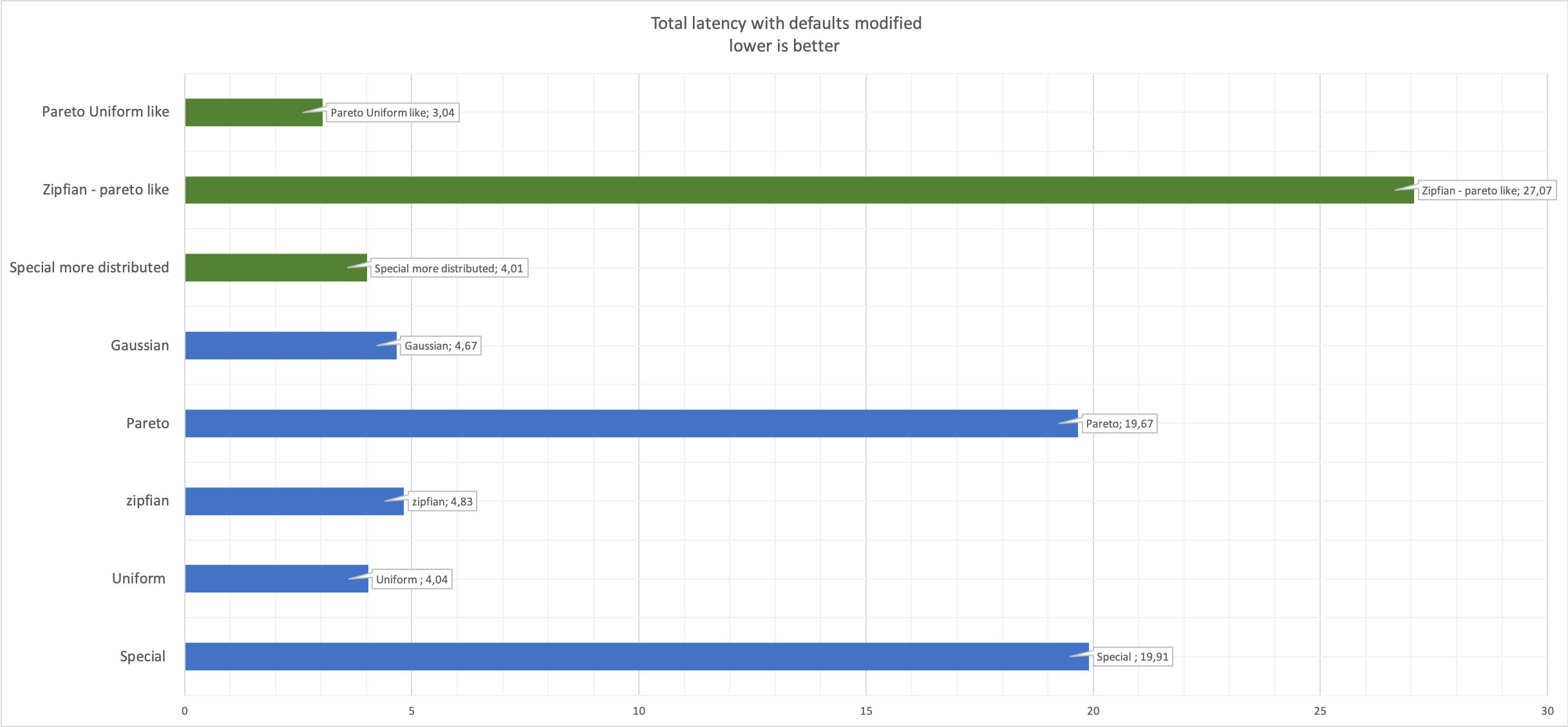
In terms of time we had (all times may have a max additional +2 seconds due the scheduler interval we had define):
- Maintenance on writer - All is done in ~700 ms no service interruption.
- Writer crash - whole failover takes 5 seconds. It may have the need to retry transactions.
- Reader crash - no service interruption
- Network issue (with PXC cluster quorum) between 7 and 10 seconds
- ProxySQL node crash - 4 seconds to fail over another ProxySQL node
Of course applications must be design to be fault tolerant and retry the transactions if any problem raise, I would say this goes without saying and is in any programming Best Practices.
If you do not do that and fully rely on the data layer, better for you to review your developers team.